We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-of-the-art performance in software engineering (SWE) issue resolving. SWE-Lego comprises three core building blocks:
Our fine-tuned models are trained exclusively with SFT from Qwen3-8B and Qwen3-32B. Their effectiveness is demonstrated on SWE-bench Verified: SWE-Lego-Qwen3-8B: 42.2% Pass@1, 49.6% TTS@16; SWE-Lego-Qwen3-32B: 52.6% Pass@1, 58.8% TTS@16. We've open-sourced everything—our dataset, code, and training scripts, for everyone to progress on scaling and improving software engineering agents.

Figure 1: SWE-Lego models establish a new frontier on SWE-bench Verified, outperforming same-scale competitors. Notably, our results are based on hack-free evaluation, whereas prior work scores could be inflated by the Git hacking.
We introduce the SWE-Lego dataset, comprising 32k high-quality software engineering task instances and 18k expert trajectories. We adopt a hybrid data construction strategy that combines real-world and synthetic SWE task instances, where both sources complement each other in quality and quantity.
Real-world instances, while authentic, are inherently limited in quantity given strict filtering criteria. Synthetic instances, while scalable, lack the complexity of natural software repositories. We therefore mix the real with synthetic instances, and apply rigorous generation and validation procedures to produce high-quality trainable trajectories.
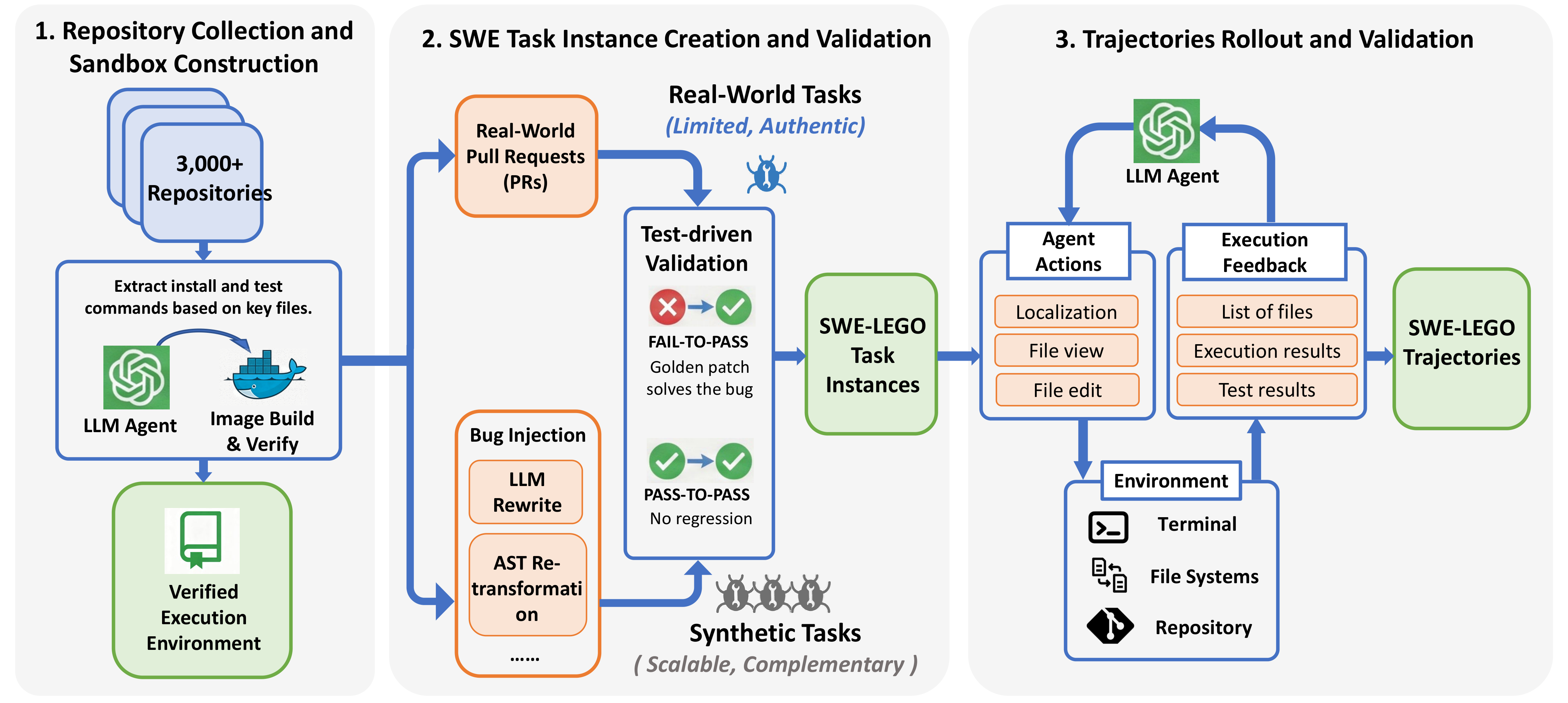
Figure 2: Our SWE‑Lego pipeline comprises three stages: environment construction from over 3,000 repositories; hybrid task creation by combining real pull requests with synthetic bugs; and expert‑trajectory generation and curation for SFT.
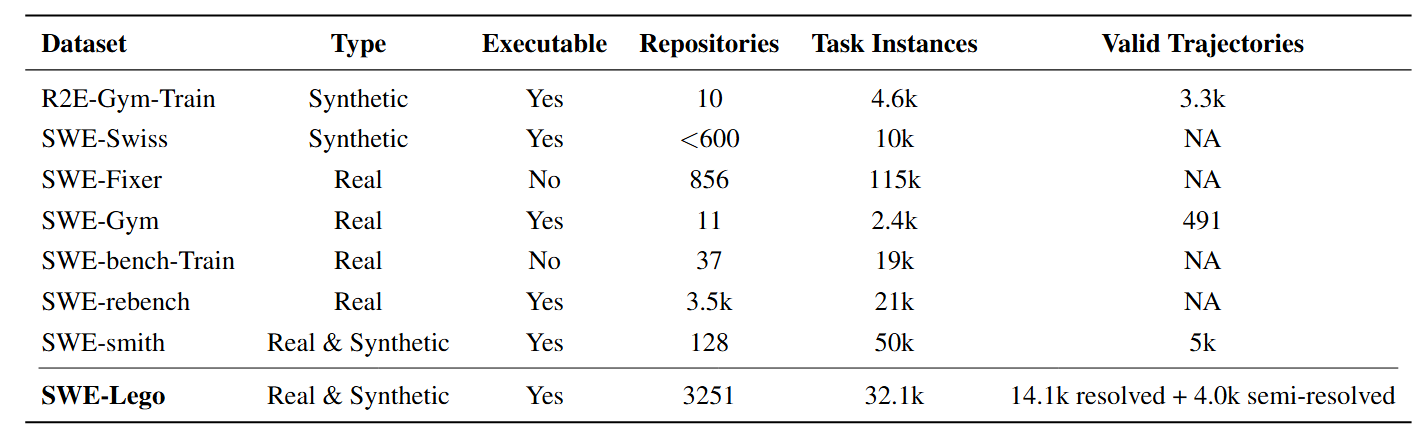
Figure 3: Comparison of public SWE issue-resolving datasets and our SWE-Lego dataset. The proposed dataset combines real and synthetic instances at scale, with executable environments and a large pool of validated trajectories.
The dataset is built upon SWE-rebench, selecting over 3,000 Python-centric repositories. We deploy a fully automated pipeline that parses configuration files to build Docker containers, ensuring reproducibility.
Real-world tasks are derived from resolved GitHub pull requests, offering high authenticity with production-level bug complexity, but are often labor-intensive and limited in quantity. Synthetic tasks are generated via active bug injection, leveraging LLM Rewrite (prompting models to rewrite code using only function headers and docstrings) and AST Reformulation (extracting abstract syntax trees and applying random transformations) techniques, enabling high scalability and efficiency. These two data sources are complementary: real-world data provides depth (complexity and realism), while synthetic data provides breadth (quantity and coverage). For a fixed set of repositories, scaling synthetic data consistently improves both the number of valid expert trajectories and the resolve rate of trained models.
We roll out expert trajectories using OpenHands scaffold with Qwen3-Coder-480B-A35B-Instruct as the teacher agent. To enhance trajectory quality, we implement three key practices: preventing Git hacking, handling malformed tool errors, and pruning ineffective tools.
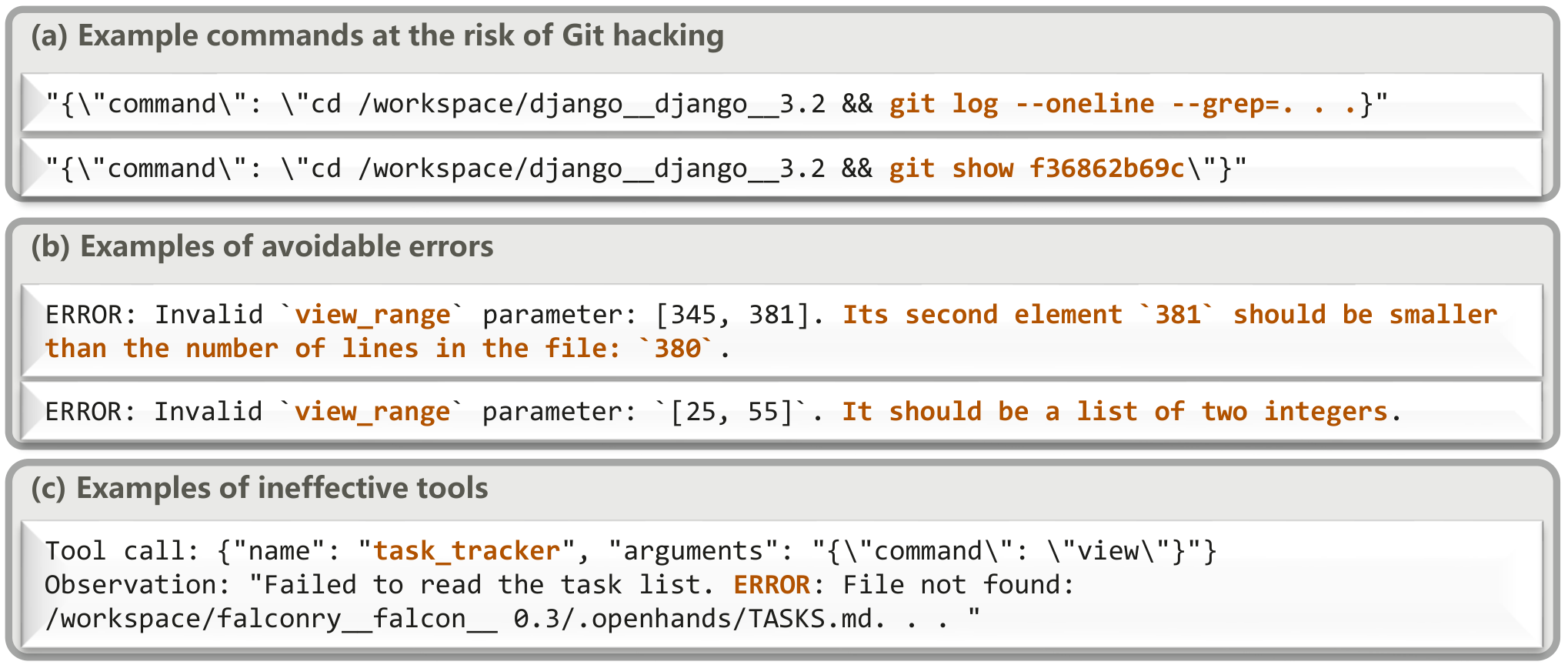
Figure 4: Examples of problematic commands or tool interactions: (a) high‑risk commands that can cause Git hacking; (b) view_range parameter mis-specification; (c) ineffective task_tracker.
Preventing Git Hacking: We sanitize repository history to prevent agents from "hacking" git metadata. For real instances, we remove commits dated after issue creation. For synthetic instances, we remove the entire git history, forcing genuine reasoning about code and tests.
Handling Malformed Tool Errors: We apply lightweight post-hoc correction for malformed tool calls, parsing strings to integers and clipping ranges to valid spans, improving code inspection reliability.
Pruning Ineffective Tools: We restrict the tool set to four essential operations: execute_bash, str_replace_editor, think, and finish, keeping trajectories streamlined.
Validation and Filtering: We filter low-quality resolved trajectories and recycle semi-resolved trajectories (correctly locating buggy files but failing to fix), resulting in 4k additional trajectories and a +1.2% performance boost.
We refine conventional SFT with two innovations: step-level error masking and difficulty-based curriculum learning. Step-level error masking enables the model to learn from correct actions while excluding incorrect ones. Our method maintains the full trajectory context but selectively masks the loss calculation on erroneous agent responses.
Expert trajectories often contain intermediate missteps. We use regular expressions to identify error messages and apply error masking to corresponding agent responses, excluding errors from reproducing bugs or executing tests. This technique applies gradient updates solely to valid actions, improving model performance by over 2 points.
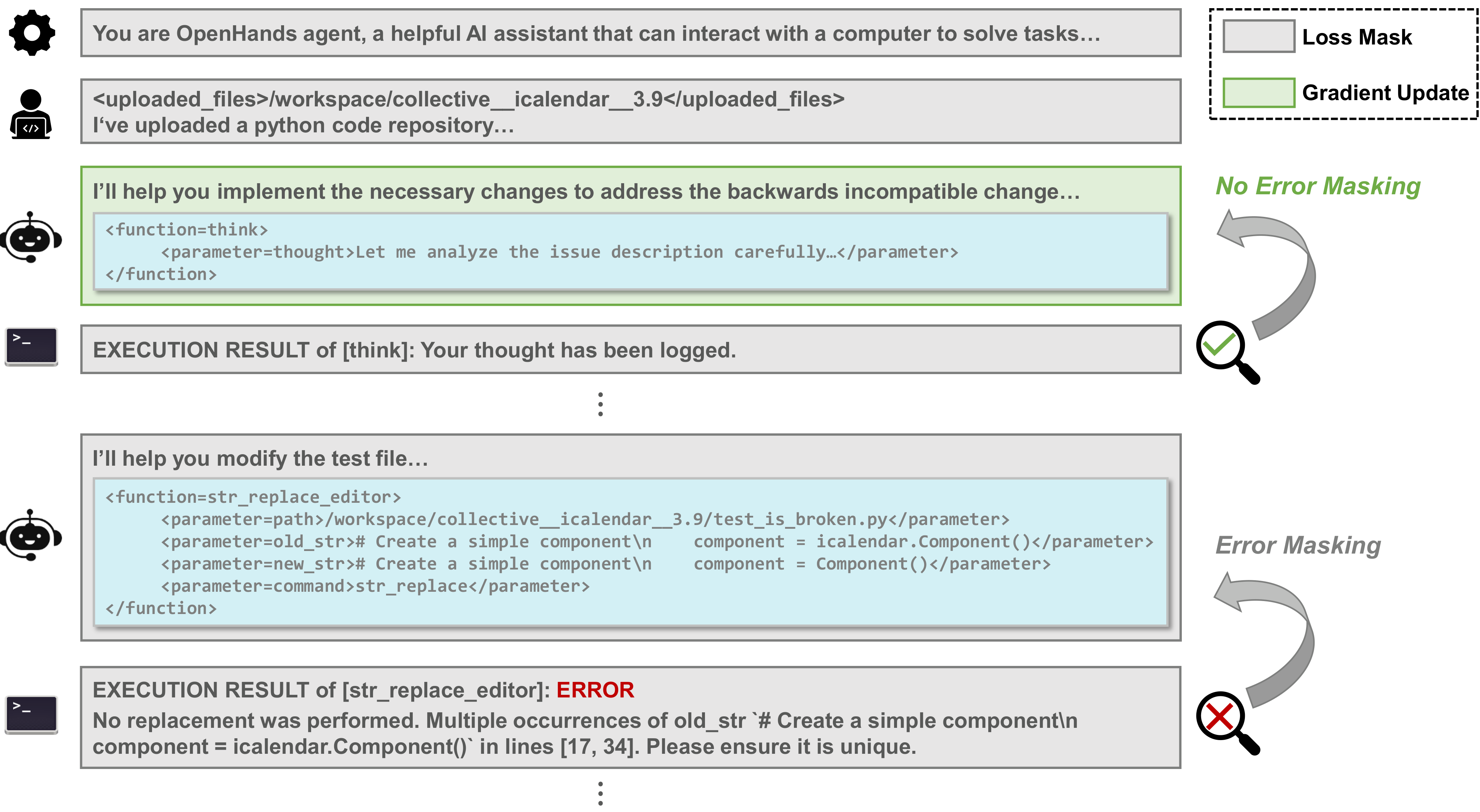
Figure 5: An example of step-level error masking, which maintains the complete trajectory context while selectively masking the loss calculation on incorrect agent responses.
We implement a curriculum learning strategy that progressively exposes the model to tasks of increasing complexity. We discover a strong negative correlation (r=-0.95) between resolve rate and trajectory length, and partition data into three difficulty bins: Easy (0-50 turns), Medium (50-70 turns), and Hard (70-100 turns).
We adopt a three-stage SFT curriculum. To mitigate catastrophic forgetting, each subsequent stage includes all data from preceding stages. This curriculum first grounds the model on "Easy" tasks, then introduces "Hard" tasks for strategic planning.
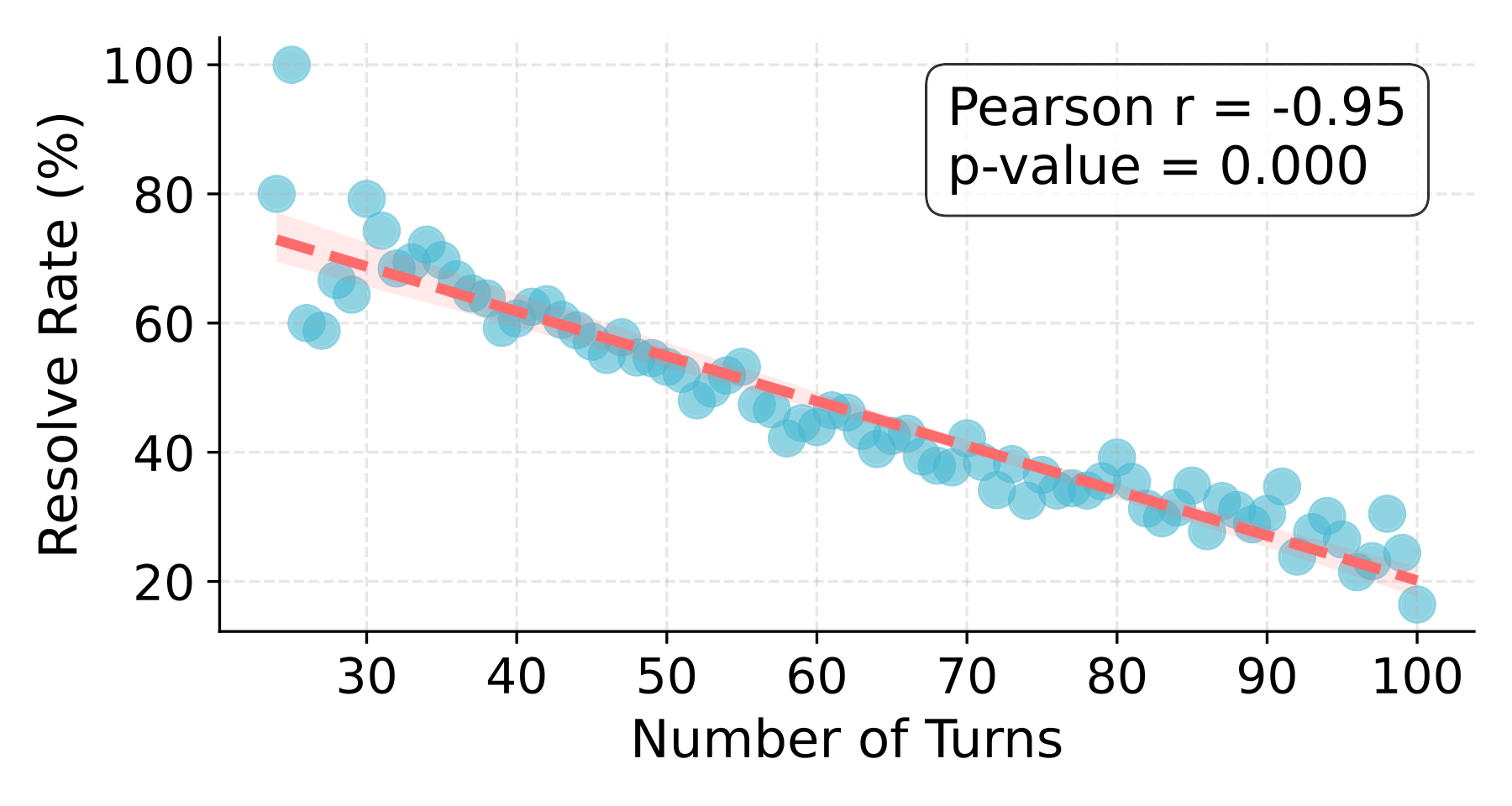
Figure 6: Correlation between number of turns and average resolve rate.
Table 1: Ablation of training strategies. The table shows resolve rates for SWE-Lego-8B and SWE-Lego-32B with different combinations of error masking and curriculum learning. The best results (42.2% for 8B and 52.6% for 32B) are achieved when both techniques are combined.
We use Qwen3-8B/32B as base models, performing full-parameter SFT using LLaMA-Factory. Models are trained for 4 epochs with a global batch size of 64, learning rate 1e-4 (8B) or 5e-5 (32B), and a maximum context length of 128k tokens.
Test-time scaling (TTS) improves SWE agent performance by allocating additional compute during inference. We investigate two complementary dimensions: sequential scaling (more interaction turns) and parallel scaling (multiple rollouts with verifier selection).
Sequential scaling is highly efficient in the low-turn regime, but performance saturates around 100–140 turns. Beyond this point, parallel scaling with verifier-based selection becomes more effective, as independent trajectories explore diverse paths through the solution space.
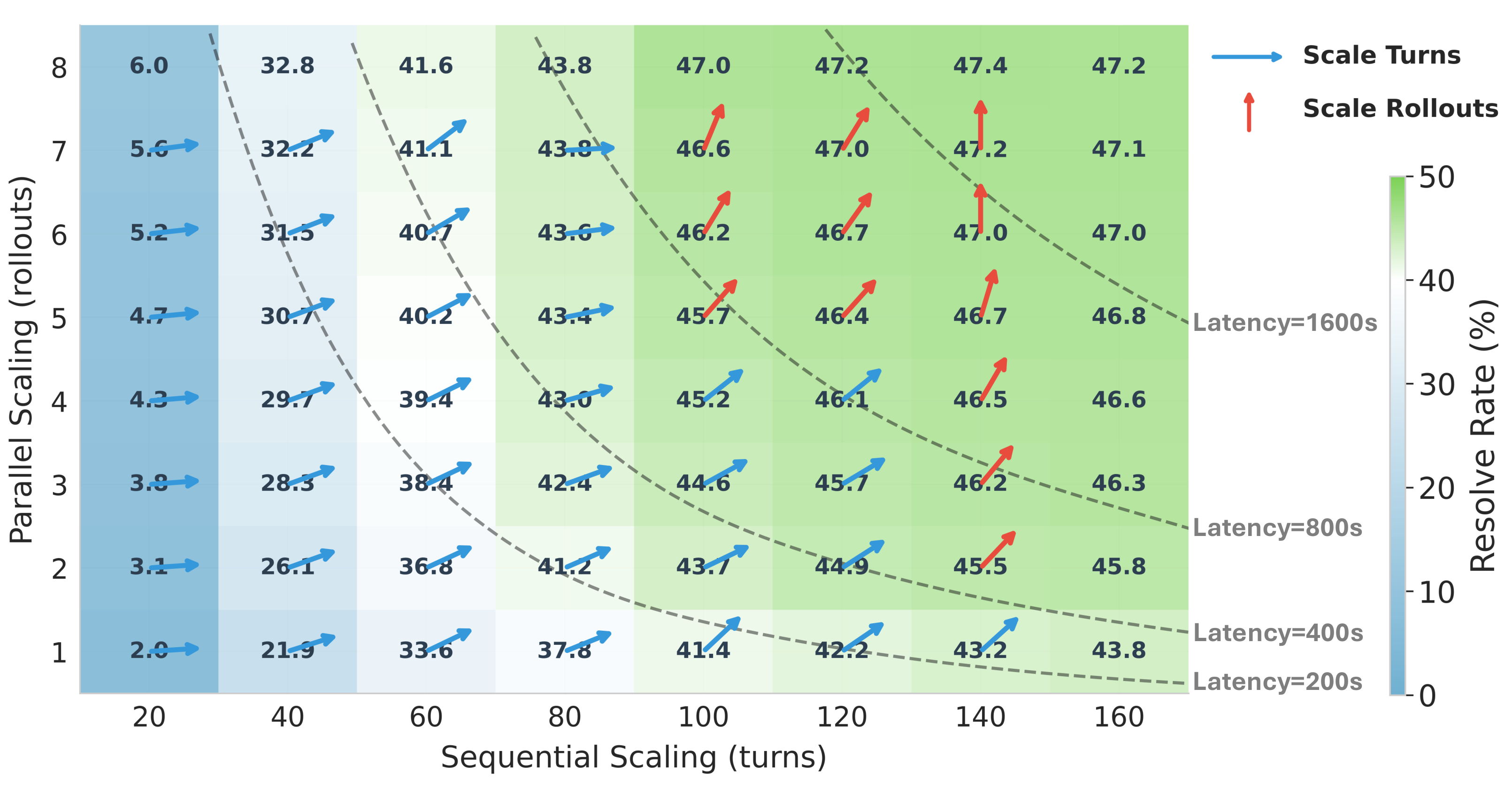
Figure 7: Resolve rate as a function of interaction turns (x-axis) and parallel rollouts (y-axis). Sequential scaling is most effective at low turn counts; after saturation, improvements are driven primarily by parallel scaling.
We compare two verifier paradigms: the regressive verifier (scoring head with binary cross-entropy) and the generative verifier (text generation predicting "yes"/"no"). The generative formulation aligns with pre-trained next-token prediction, better leveraging the model's inherent knowledge.
The generative verifier consistently outperforms the regressive one. On SWE-Lego-Qwen3-8B, the gap reaches 2.8% at K=16 (49.6% vs. 46.8%). We adopt the generative paradigm.
SWE-Lego-Verifier-8B achieves TTS@16 of 49.6%, outperforming OpenHands-Critic-32B (44.0%) and R2E-Gym-Verifier-14B (47.0%). Generative verifiers maintain monotonic improvement, confirming more robust scaling properties.
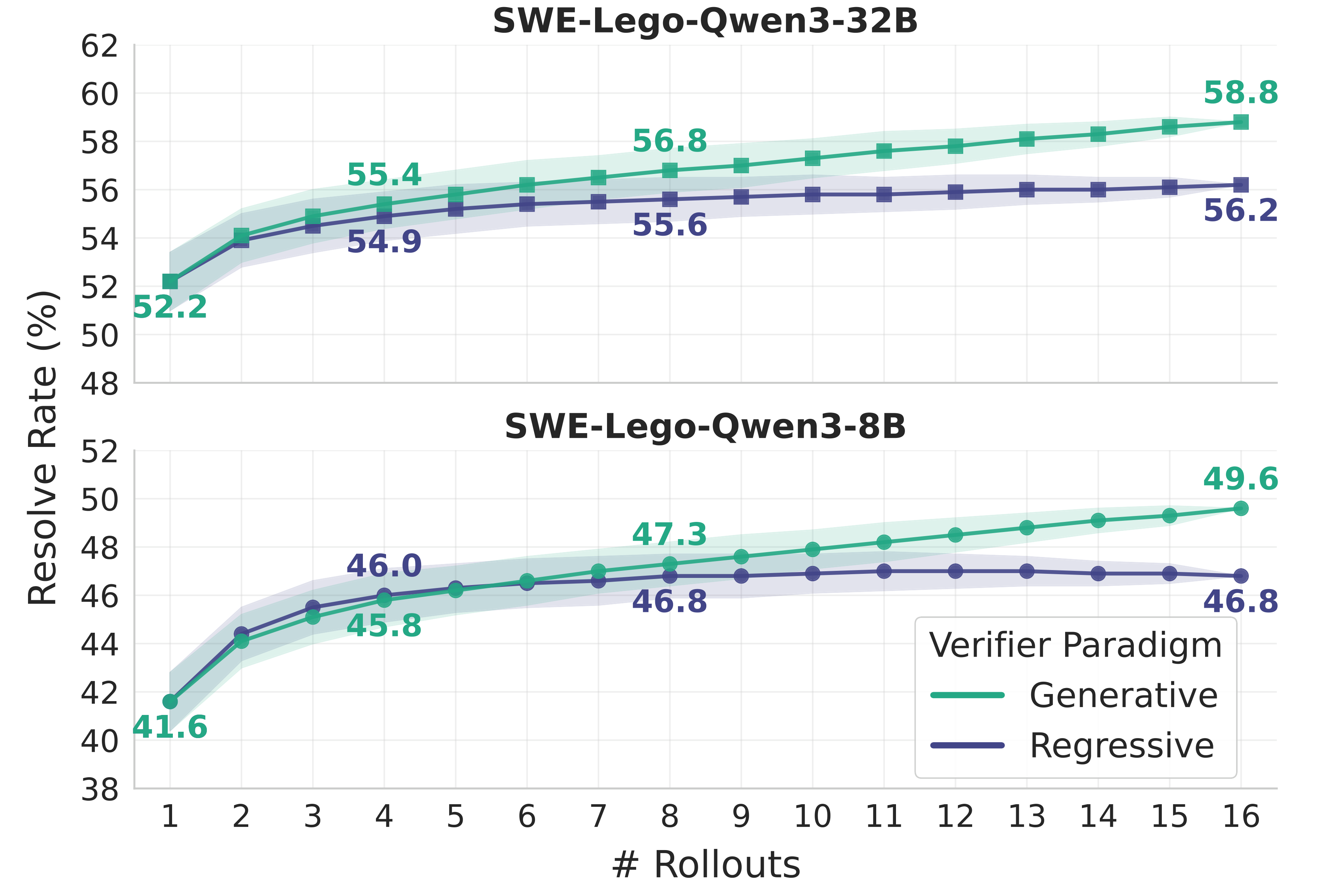
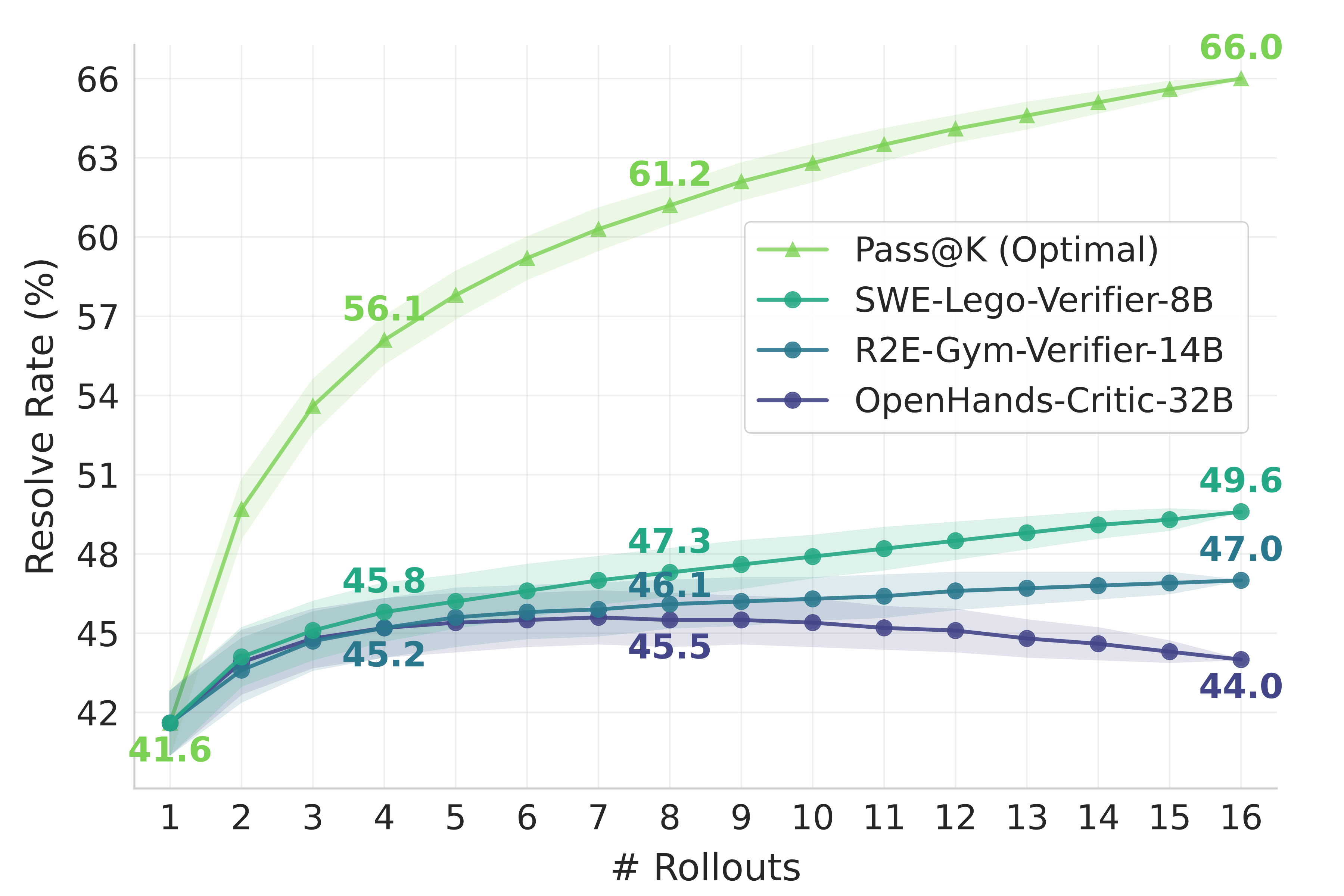
Figure 8: Parallel TTS performance on SWE-bench Verified. (a) Generative verifiers consistently outperform regressive counterparts. (b) SWE-Lego-Verifier-8B outperforms OpenHands-Critic-32B and R2E-Gym-Verifier-14B.
We compare SWE-Lego models with both proprietary and open-source baselines on SWE-bench Verified. Our results are reported without Git hacking for fair comparison. SWE-Lego-Qwen3-8B achieves 42.2% with SFT and 49.6% with TTS@16, while SWE-Lego-Qwen3-32B attains 52.6% with SFT and 58.8% with TTS@16. These hack-free results surpass most open-source models and several larger proprietary models.
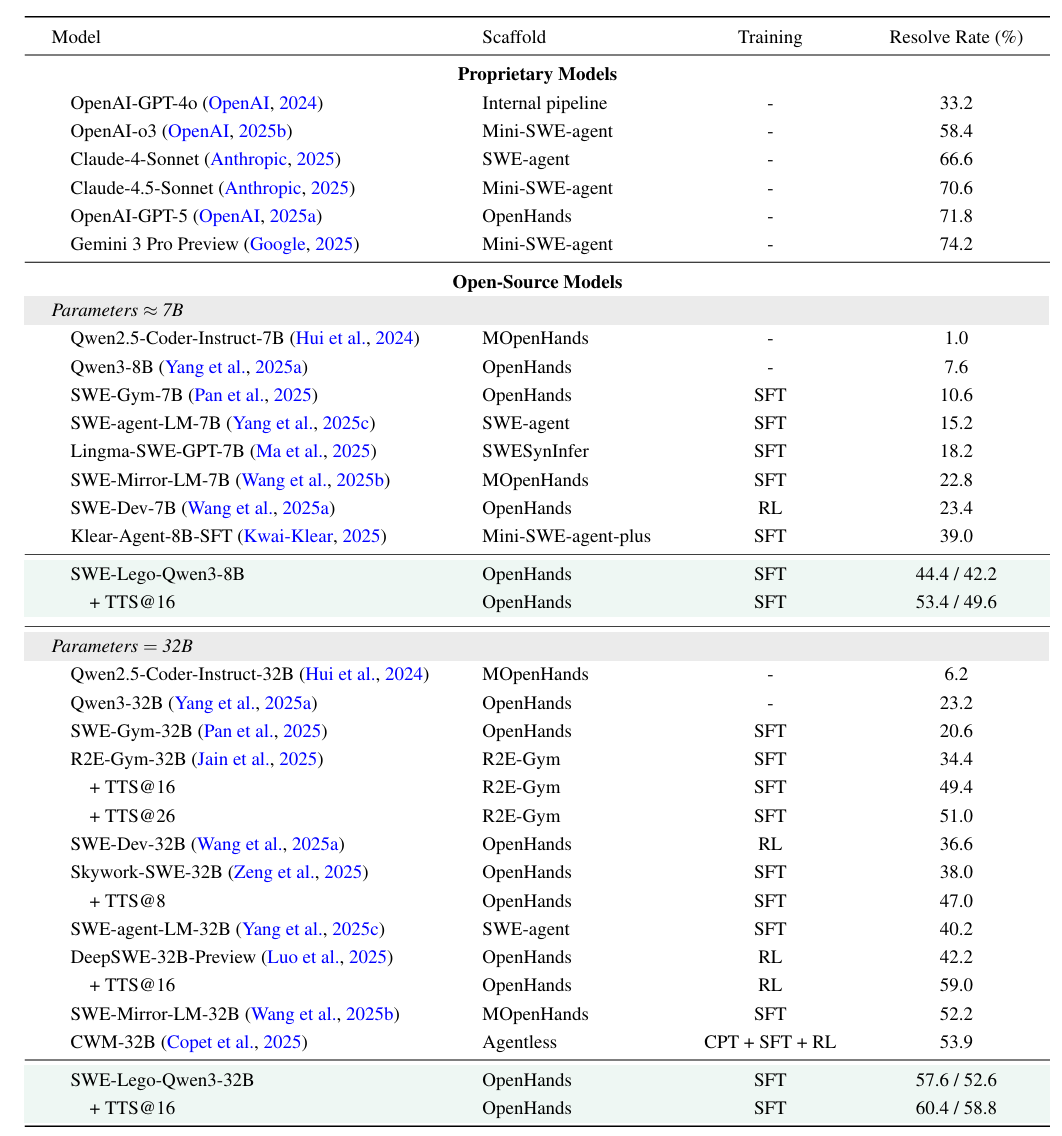
Figure 9: Performance comparison on the SWE-bench Verified. Our results are reported in the "A/B" format, representing the results with and without Git hacking respectively.
@misc{swelego,
title={SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving},
author={Chaofan Tao and Jierun Chen and Yuxin Jiang and Kaiqi Kou and Shaowei Wang and Ruoyu Wang and Xiaohui Li and Sidi Yang and Yiming Du and Jianbo Dai and Zhiming Mao and Xinyu Wang and Lifeng Shang and Haoli Bai},
year={2026},
eprint={2601.01426},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2601.01426},
}