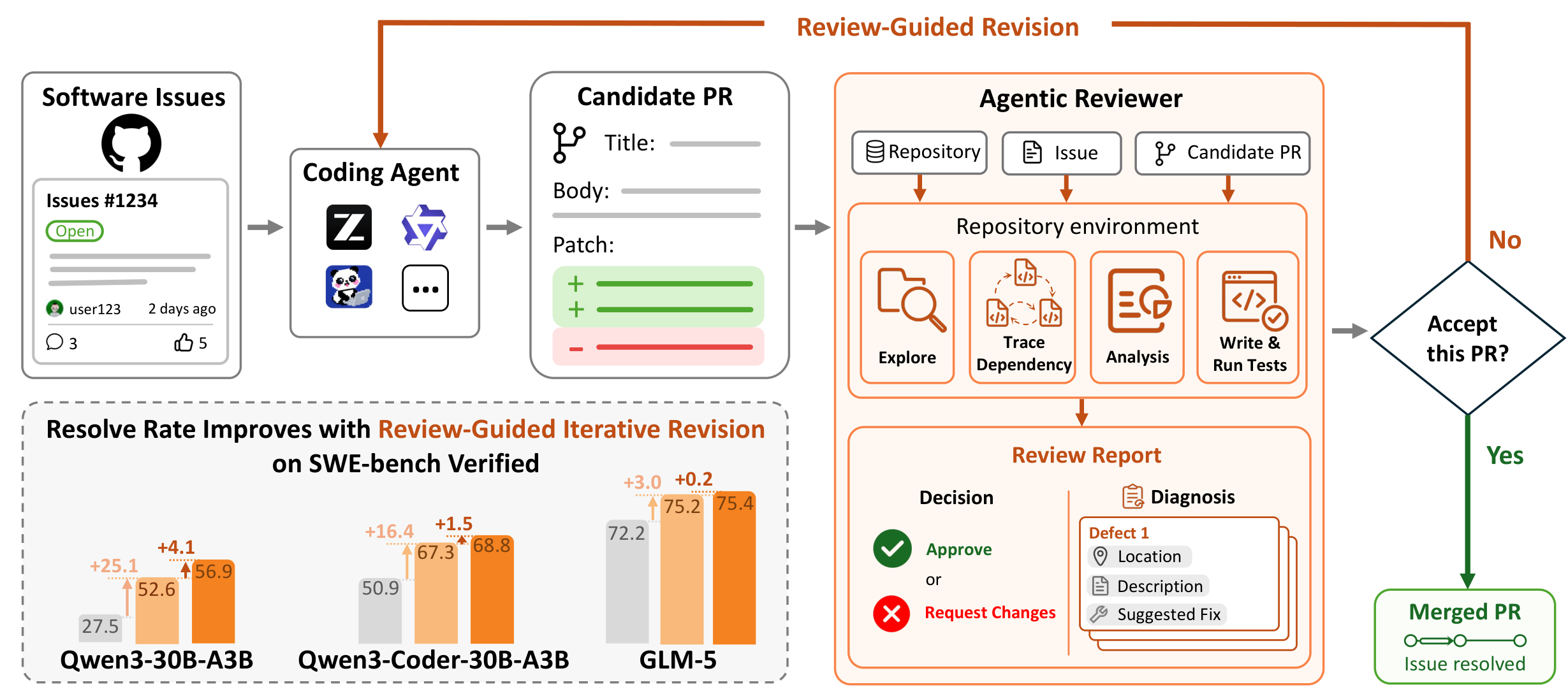
Closing the Loop Works — The generate–review–revise loop continuously improves PRs, raising resolve rate by up to +29.4 percentage points on SWE-bench Verified.
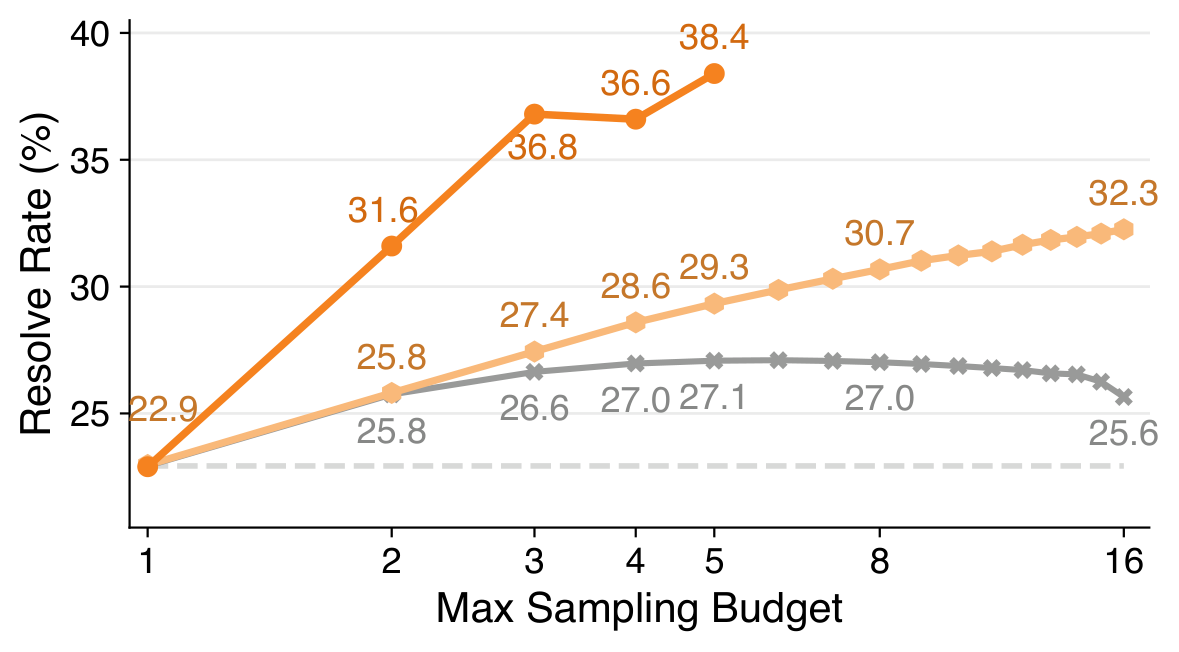
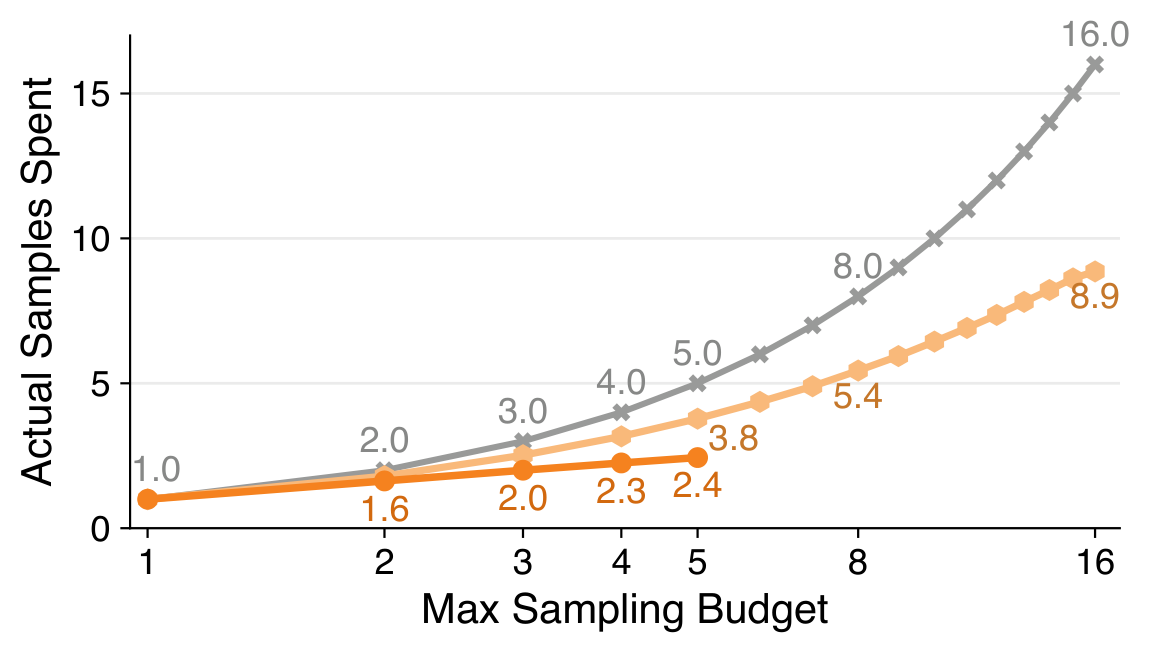
Structured Diagnoses Enable Efficient Test-Time Scaling — Review-guided iterative revision achieves 3.7× the test-time scaling gain at 6.7× the efficiency of independent resampling.
Review Trajectories Transfer to Issue Resolution — Mixed training with review data improves one-shot resolve rate (+5.6pp) and enables self-contained review-revise loops within a single model (+10.6pp).